Dehong Xu
Machine Learning Researcher, Apple AIML
Ph.D. from UCLA
Email: xudehong1996@ucla.edu
Google Scholar LinkedIn GitHub

I am a Machine Learning Reseacher at 🍎Apple AIML, working on LLM post-training and reasoning. I received my Ph.D. from UCLA, advised by Prof. Ying Nian Wu.
I am mainly interested in the intersections of language modeling, representation learning, and decision-making. My recent research is focused on building powerful Generative AI models to understand, reason and collaborate with humans. Specifically, my research topics include:
🌟 I will attend NeurIPS 2025 (Decmber 2 - Decmber 7) at San Diego. Please DM if you'd like to have a coffee chat!

@article{kong2025latent,
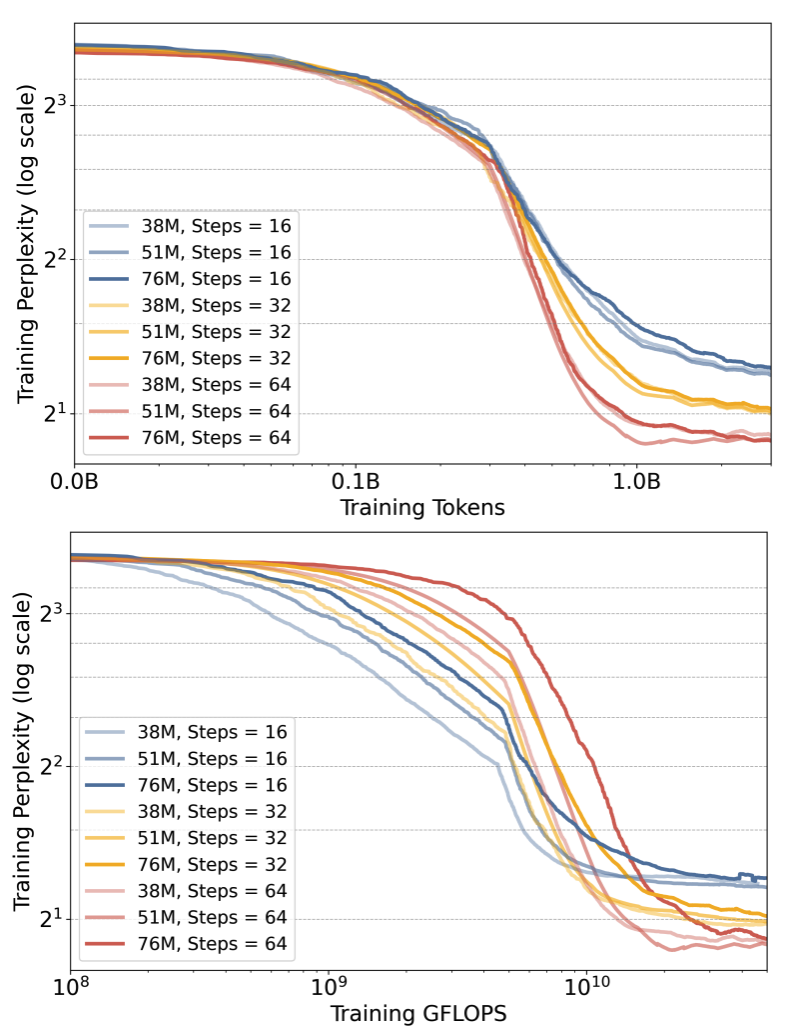
title={Latent Thought Models with Variational Bayes Inference-Time Computation},
author={Kong, Deqian and Zhao, Minglu and Xu, Dehong and Pang, Bo and Wang, Shu and Honig, Edouardo and Si, Zhangzhang and Li, Chuan and Xie, Jianwen and Xie, Sirui and others},
journal={arXiv preprint arXiv:2502.01567},
year={2025}
}
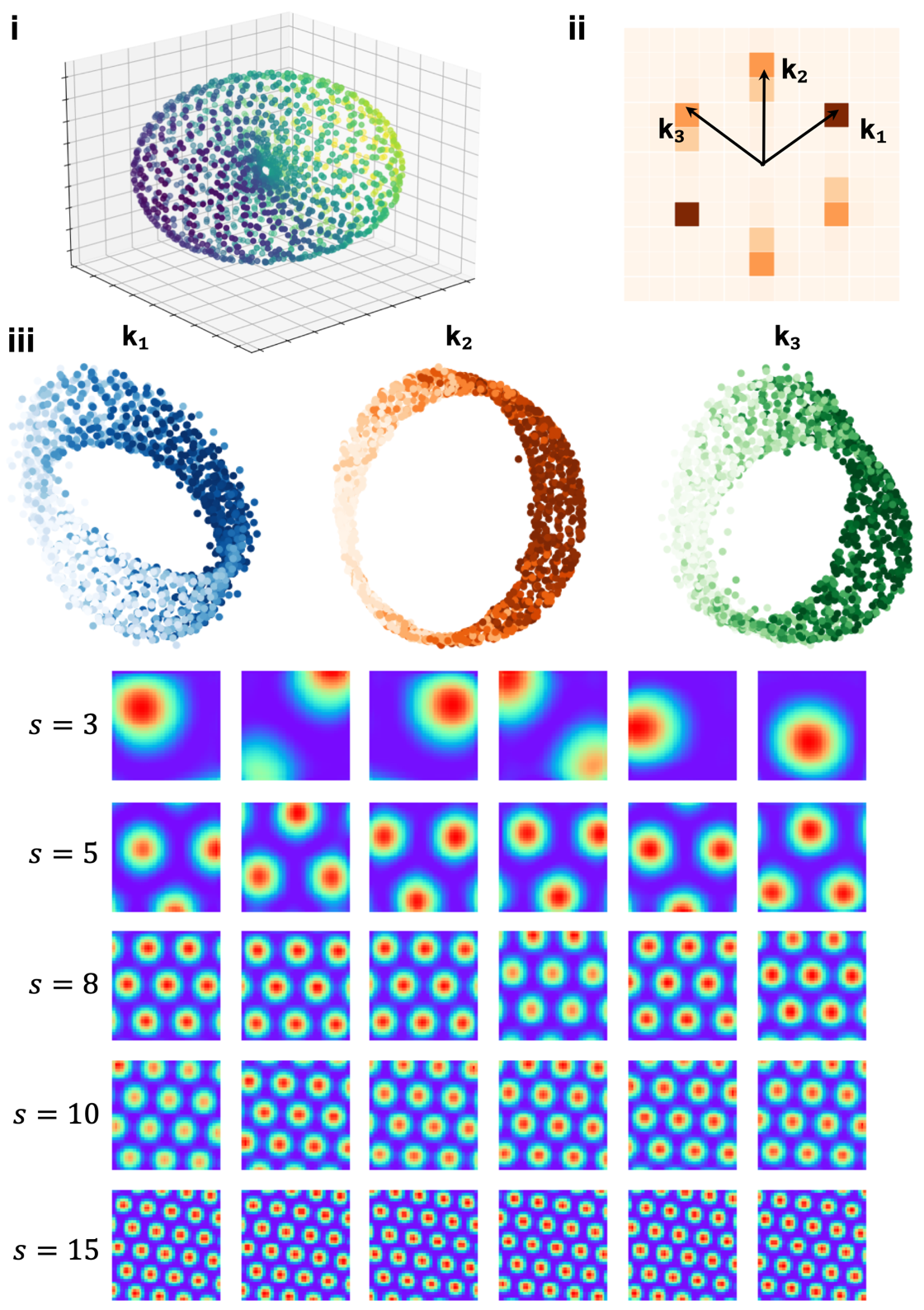
@inproceedings{xuconformal,
title={On Conformal Isometry of Grid Cells: Learning Distance-Preserving Position Embedding},
author={Xu, Dehong and Gao, Ruiqi and Zhang, Wenhao and Wei, Xue-Xin and Wu, Ying Nian},
booktitle={The Thirteenth International Conference on Learning Representations}
}
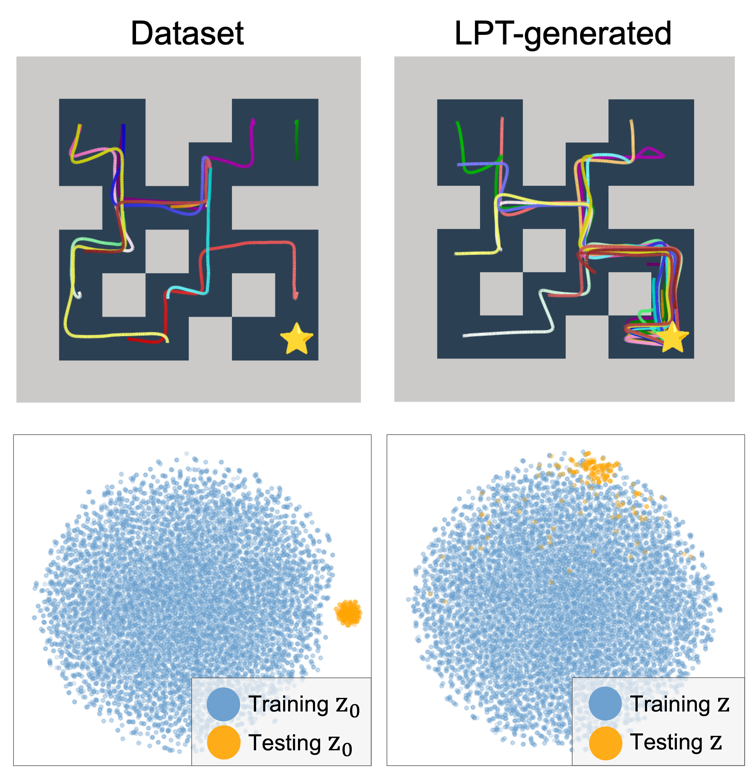
@article{kong2024latent,
title={Latent Plan Transformer for Trajectory Abstraction: Planning as Latent Space Inference},
author={Kong, Deqian and Xu, Dehong and Zhao, Minglu and Pang, Bo and Xie, Jianwen and Lizarraga, Andrew and Huang, Yuhao and Xie, Sirui and Wu, Ying Nian},
journal={Advances in Neural Information Processing Systems},
year={2024}
}
@article{xu2024aligning,
title={Aligning Large Language Models via Fine-grained Supervision},
author={Xu, Dehong and Qiu, Liang and Kim, Minseok and Ladhak, Faisal and Do, Jaeyoung},
journal={arXiv preprint arXiv:2406.02756},
year={2024}
}
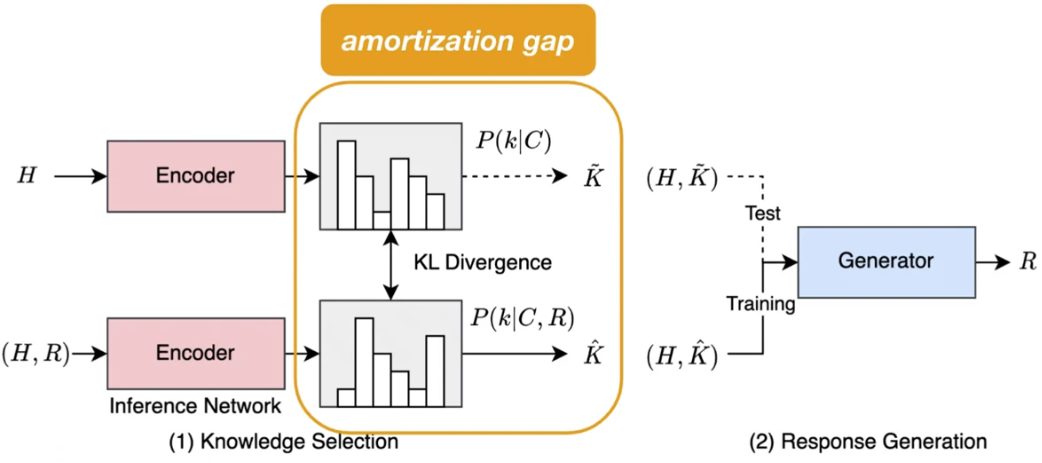
@inproceedings{xu2023diverse,
title={Diverse and faithful knowledge-grounded dialogue generation via sequential posterior inference},
author={Xu, Yan and Kong, Deqian and Xu, Dehong and Ji, Ziwei and Pang, Bo and Fung, Pascale and Wu, Ying Nian},
booktitle={International Conference on Machine Learning},
pages={38518--38534},
year={2023},
organization={PMLR}
}